 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgechange detection for hyperspectral images
Papers and Code
SpecAware: A Spectral-Content Aware Foundation Model for Unifying Multi-Sensor Learning in Hyperspectral Remote Sensing Mapping
Oct 31, 2025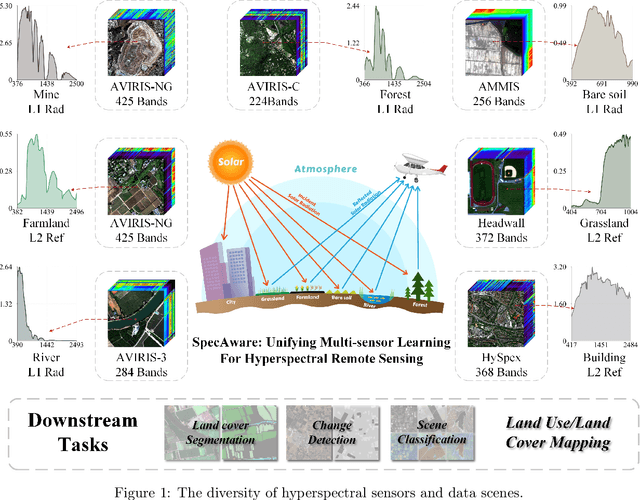
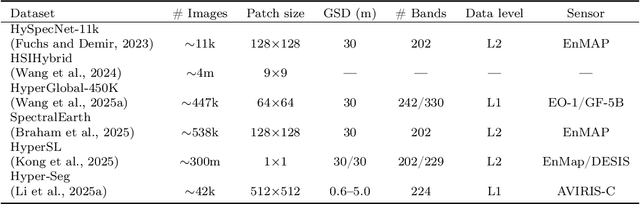
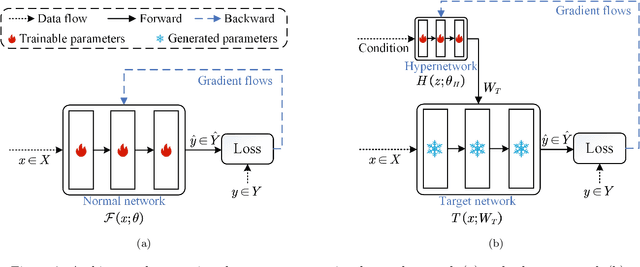

Hyperspectral imaging (HSI) is a vital tool for fine-grained land-use and land-cover (LULC) mapping. However, the inherent heterogeneity of HSI data has long posed a major barrier to developing generalized models via joint training. Although HSI foundation models have shown promise for different downstream tasks, the existing approaches typically overlook the critical guiding role of sensor meta-attributes, and struggle with multi-sensor training, limiting their transferability. To address these challenges, we propose SpecAware, which is a novel hyperspectral spectral-content aware foundation model for unifying multi-sensor learning for HSI mapping. We also constructed the Hyper-400K dataset to facilitate this research, which is a new large-scale, high-quality benchmark dataset with over 400k image patches from diverse airborne AVIRIS sensors. The core of SpecAware is a two-step hypernetwork-driven encoding process for HSI data. Firstly, we designed a meta-content aware module to generate a unique conditional input for each HSI patch, tailored to each spectral band of every sample by fusing the sensor meta-attributes and its own image content. Secondly, we designed the HyperEmbedding module, where a sample-conditioned hypernetwork dynamically generates a pair of matrix factors for channel-wise encoding, consisting of adaptive spatial pattern extraction and latent semantic feature re-projection. Thus, SpecAware gains the ability to perceive and interpret spatial-spectral features across diverse scenes and sensors. This, in turn, allows SpecAware to adaptively process a variable number of spectral channels, establishing a unified framework for joint pre-training. Extensive experiments on six datasets demonstrate that SpecAware can learn superior feature representations, excelling in land-cover semantic segmentation classification, change detection, and scene classification.
Curriculum Multi-Task Self-Supervision Improves Lightweight Architectures for Onboard Satellite Hyperspectral Image Segmentation
Sep 16, 2025



Hyperspectral imaging (HSI) captures detailed spectral signatures across hundreds of contiguous bands per pixel, being indispensable for remote sensing applications such as land-cover classification, change detection, and environmental monitoring. Due to the high dimensionality of HSI data and the slow rate of data transfer in satellite-based systems, compact and efficient models are required to support onboard processing and minimize the transmission of redundant or low-value data, e.g. cloud-covered areas. To this end, we introduce a novel curriculum multi-task self-supervised learning (CMTSSL) framework designed for lightweight architectures for HSI analysis. CMTSSL integrates masked image modeling with decoupled spatial and spectral jigsaw puzzle solving, guided by a curriculum learning strategy that progressively increases data complexity during self-supervision. This enables the encoder to jointly capture fine-grained spectral continuity, spatial structure, and global semantic features. Unlike prior dual-task SSL methods, CMTSSL simultaneously addresses spatial and spectral reasoning within a unified and computationally efficient design, being particularly suitable for training lightweight models for onboard satellite deployment. We validate our approach on four public benchmark datasets, demonstrating consistent gains in downstream segmentation tasks, using architectures that are over 16,000x lighter than some state-of-the-art models. These results highlight the potential of CMTSSL in generalizable representation learning with lightweight architectures for real-world HSI applications. Our code is publicly available at https://github.com/hugocarlesso/CMTSSL.
Advancing Wheat Crop Analysis: A Survey of Deep Learning Approaches Using Hyperspectral Imaging
May 01, 2025As one of the most widely cultivated and consumed crops, wheat is essential to global food security. However, wheat production is increasingly challenged by pests, diseases, climate change, and water scarcity, threatening yields. Traditional crop monitoring methods are labor-intensive and often ineffective for early issue detection. Hyperspectral imaging (HSI) has emerged as a non-destructive and efficient technology for remote crop health assessment. However, the high dimensionality of HSI data and limited availability of labeled samples present notable challenges. In recent years, deep learning has shown great promise in addressing these challenges due to its ability to extract and analysis complex structures. Despite advancements in applying deep learning methods to HSI data for wheat crop analysis, no comprehensive survey currently exists in this field. This review addresses this gap by summarizing benchmark datasets, tracking advancements in deep learning methods, and analyzing key applications such as variety classification, disease detection, and yield estimation. It also highlights the strengths, limitations, and future opportunities in leveraging deep learning methods for HSI-based wheat crop analysis. We have listed the current state-of-the-art papers and will continue tracking updating them in the following https://github.com/fadi-07/Awesome-Wheat-HSI-DeepLearning.
Global and Local Attention-Based Transformer for Hyperspectral Image Change Detection
Nov 21, 2024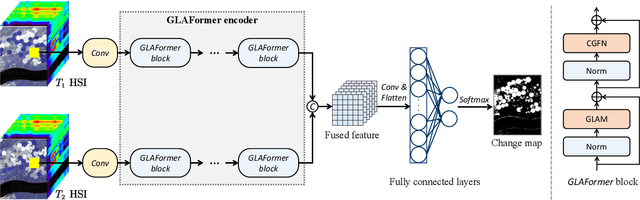
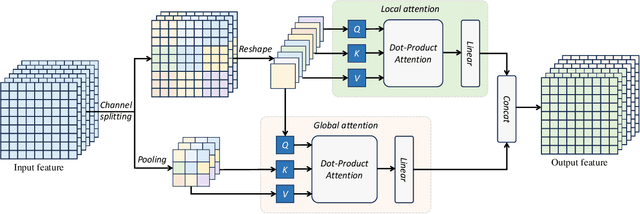
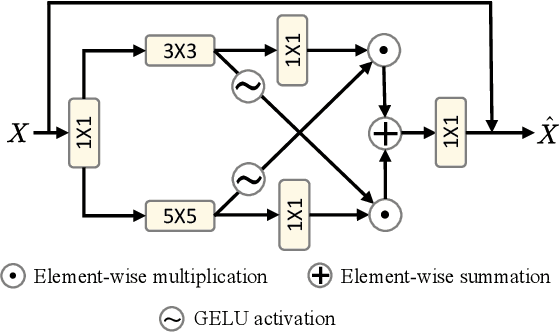
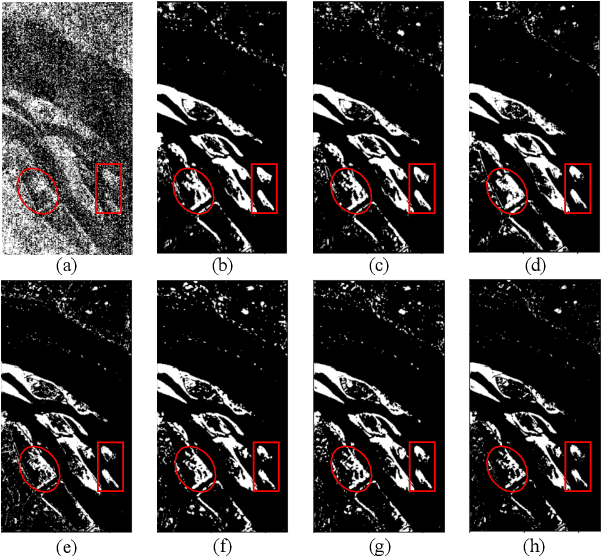
Recently Transformer-based hyperspectral image (HSI) change detection methods have shown remarkable performance. Nevertheless, existing attention mechanisms in Transformers have limitations in local feature representation. To address this issue, we propose Global and Local Attention-based Transformer (GLAFormer), which incorporates a global and local attention module (GLAM) to combine high-frequency and low-frequency signals. Furthermore, we introduce a cross-gating mechanism, called cross-gated feed-forward network (CGFN), to emphasize salient features and suppress noise interference. Specifically, the GLAM splits attention heads into global and local attention components to capture comprehensive spatial-spectral features. The global attention component employs global attention on downsampled feature maps to capture low-frequency information, while the local attention component focuses on high-frequency details using non-overlapping window-based local attention. The CGFN enhances the feature representation via convolutions and cross-gating mechanism in parallel paths. The proposed GLAFormer is evaluated on three HSI datasets. The results demonstrate its superiority over state-of-the-art HSI change detection methods. The source code of GLAFormer is available at \url{https://github.com/summitgao/GLAFormer}.
SpecDM: Hyperspectral Dataset Synthesis with Pixel-level Semantic Annotations
Feb 24, 2025In hyperspectral remote sensing field, some downstream dense prediction tasks, such as semantic segmentation (SS) and change detection (CD), rely on supervised learning to improve model performance and require a large amount of manually annotated data for training. However, due to the needs of specific equipment and special application scenarios, the acquisition and annotation of hyperspectral images (HSIs) are often costly and time-consuming. To this end, our work explores the potential of generative diffusion model in synthesizing HSIs with pixel-level annotations. The main idea is to utilize a two-stream VAE to learn the latent representations of images and corresponding masks respectively, learn their joint distribution during the diffusion model training, and finally obtain the image and mask through their respective decoders. To the best of our knowledge, it is the first work to generate high-dimensional HSIs with annotations. Our proposed approach can be applied in various kinds of dataset generation. We select two of the most widely used dense prediction tasks: semantic segmentation and change detection, and generate datasets suitable for these tasks. Experiments demonstrate that our synthetic datasets have a positive impact on the improvement of these downstream tasks.
AI-Driven HSI: Multimodality, Fusion, Challenges, and the Deep Learning Revolution
Feb 09, 2025



Hyperspectral imaging (HSI) captures spatial and spectral data, enabling analysis of features invisible to conventional systems. The technology is vital in fields such as weather monitoring, food quality control, counterfeit detection, healthcare diagnostics, and extending into defense, agriculture, and industrial automation at the same time. HSI has advanced with improvements in spectral resolution, miniaturization, and computational methods. This study provides an overview of the HSI, its applications, challenges in data fusion and the role of deep learning models in processing HSI data. We discuss how integration of multimodal HSI with AI, particularly with deep learning, improves classification accuracy and operational efficiency. Deep learning enhances HSI analysis in areas like feature extraction, change detection, denoising unmixing, dimensionality reduction, landcover mapping, data augmentation, spectral construction and super resolution. An emerging focus is the fusion of hyperspectral cameras with large language models (LLMs), referred as highbrain LLMs, enabling the development of advanced applications such as low visibility crash detection and face antispoofing. We also highlight key players in HSI industry, its compound annual growth rate and the growing industrial significance. The purpose is to offer insight to both technical and non-technical audience, covering HSI's images, trends, and future directions, while providing valuable information on HSI datasets and software libraries.
Quantum Information-Empowered Graph Neural Network for Hyperspectral Change Detection
Nov 12, 2024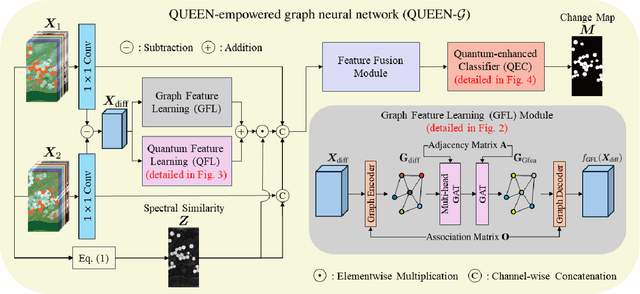

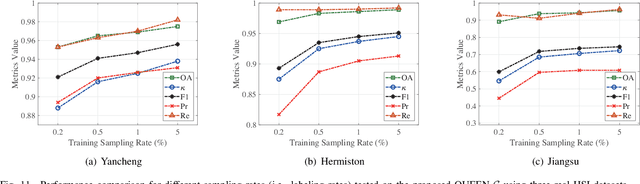
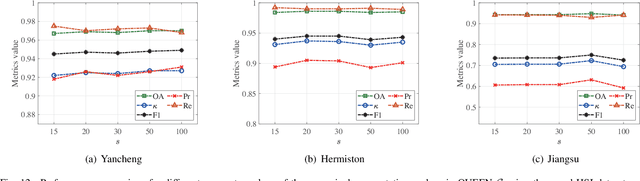
Change detection (CD) is a critical remote sensing technique for identifying changes in the Earth's surface over time. The outstanding substance identifiability of hyperspectral images (HSIs) has significantly enhanced the detection accuracy, making hyperspectral change detection (HCD) an essential technology. The detection accuracy can be further upgraded by leveraging the graph structure of HSIs, motivating us to adopt the graph neural networks (GNNs) in solving HCD. For the first time, this work introduces quantum deep network (QUEEN) into HCD. Unlike GNN and CNN, both extracting the affine-computing features, QUEEN provides fundamentally different unitary-computing features. We demonstrate that through the unitary feature extraction procedure, QUEEN provides radically new information for deciding whether there is a change or not. Hierarchically, a graph feature learning (GFL) module exploits the graph structure of the bitemporal HSIs at the superpixel level, while a quantum feature learning (QFL) module learns the quantum features at the pixel level, as a complementary to GFL by preserving pixel-level detailed spatial information not retained in the superpixels. In the final classification stage, a quantum classifier is designed to cooperate with a traditional fully connected classifier. The superior HCD performance of the proposed QUEEN-empowered GNN (i.e., QUEEN-G) will be experimentally demonstrated on real hyperspectral datasets.
Exploring Fully Convolutional Networks for the Segmentation of Hyperspectral Imaging Applied to Advanced Driver Assistance Systems
Dec 05, 2024Advanced Driver Assistance Systems (ADAS) are designed with the main purpose of increasing the safety and comfort of vehicle occupants. Most of current computer vision-based ADAS perform detection and tracking tasks quite successfully under regular conditions, but are not completely reliable, particularly under adverse weather and changing lighting conditions, neither in complex situations with many overlapping objects. In this work we explore the use of hyperspectral imaging (HSI) in ADAS on the assumption that the distinct near infrared (NIR) spectral reflectances of different materials can help to better separate the objects in a driving scene. In particular, this paper describes some experimental results of the application of fully convolutional networks (FCN) to the image segmentation of HSI for ADAS applications. More specifically, our aim is to investigate to what extent the spatial features codified by convolutional filters can be helpful to improve the performance of HSI segmentation systems. With that aim, we use the HSI-Drive v1.1 dataset, which provides a set of labelled images recorded in real driving conditions with a small-size snapshot NIR-HSI camera. Finally, we analyze the implementability of such a HSI segmentation system by prototyping the developed FCN model together with the necessary hyperspectral cube preprocessing stage and characterizing its performance on an MPSoC.
* arXiv admin note: text overlap with arXiv:2411.19274
On-chip Hyperspectral Image Segmentation with Fully Convolutional Networks for Scene Understanding in Autonomous Driving
Nov 28, 2024Most of current computer vision-based advanced driver assistance systems (ADAS) perform detection and tracking of objects quite successfully under regular conditions. However, under adverse weather and changing lighting conditions, and in complex situations with many overlapping objects, these systems are not completely reliable. The spectral reflectance of the different objects in a driving scene beyond the visible spectrum can offer additional information to increase the reliability of these systems, especially under challenging driving conditions. Furthermore, this information may be significant enough to develop vision systems that allow for a better understanding and interpretation of the whole driving scene. In this work we explore the use of snapshot, video-rate hyperspectral imaging (HSI) cameras in ADAS on the assumption that the near infrared (NIR) spectral reflectance of different materials can help to better segment the objects in real driving scenarios. To do this, we have used the HSI-Drive 1.1 dataset to perform various experiments on spectral classification algorithms. However, the information retrieval of hyperspectral recordings in natural outdoor scenarios is challenging, mainly because of deficient colour constancy and other inherent shortcomings of current snapshot HSI technology, which poses some limitations to the development of pure spectral classifiers. In consequence, in this work we analyze to what extent the spatial features codified by standard, tiny fully convolutional network (FCN) models can improve the performance of HSI segmentation systems for ADAS applications. The abstract above is truncated due to submission limits. For the full abstract, please refer to the published article.
SpectralKAN: Kolmogorov-Arnold Network for Hyperspectral Images Change Detection
Jul 01, 2024



It has been verified that deep learning methods, including convolutional neural networks (CNNs), graph neural networks (GNNs), and transformers, can accurately extract features from hyperspectral images (HSIs). These algorithms perform exceptionally well on HSIs change detection (HSIs-CD). However, the downside of these impressive results is the enormous number of parameters, FLOPs, GPU memory, training and test times required. In this paper, we propose an spectral Kolmogorov-Arnold Network for HSIs-CD (SpectralKAN). SpectralKAN represent a multivariate continuous function with a composition of activation functions to extract HSIs feature and classification. These activation functions are b-spline functions with different parameters that can simulate various functions. In SpectralKAN, a KAN encoder is proposed to enhance computational efficiency for HSIs. And a spatial-spectral KAN encoder is introduced, where the spatial KAN encoder extracts spatial features and compresses the spatial dimensions from patch size to one. The spectral KAN encoder then extracts spectral features and classifies them into changed and unchanged categories. We use five HSIs-CD datasets to verify the effectiveness of SpectralKAN. Experimental verification has shown that SpectralKAN maintains high HSIs-CD accuracy while requiring fewer parameters, FLOPs, GPU memory, training and testing times, thereby increasing the efficiency of HSIs-CD. The code will be available at https://github.com/yanhengwang-heu/SpectralKAN.